
Attackers are getting creative with their AitM phishing toolkits, using several tricks to hide from the prying eyes of security teams and threat intelligence vendors. We decided to pick apart one toolkit to see exactly how it tries to hide its malicious intent.
Attackers are getting creative with their AitM phishing toolkits, using several tricks to hide from the prying eyes of security teams and threat intelligence vendors. We decided to pick apart one toolkit to see exactly how it tries to hide its malicious intent.
It’s been well reported that identity attacks are on the rise, and constantly evolving phishing tools and techniques are a big part of this. In particular, the increasing prevalence of MFA has led to AitM phishing attacks becoming much more common. The threat intelligence industry naturally wants to locate and shutdown all the phishing servers – but the phishers are fighting back.
Before we dive into how AitM phishing kits evade detection, you should check out our earlier blog post on ‘Phishing 2.0 – how phishing toolkits are evolving with AitM’ if you want to get up to speed with what these toolkits are, and why attackers are using them more regularly.
In this blog post, we’re going to look at a recent instance of the NakedPages AitM phishing toolkit and some of the steps it takes to frustrate detection and analysis. In particular, we’ll look at how malicious activity is obfuscated through the use of legitimate SaaS services. NakedPages uses a range of different techniques and so serves as a good case study as to how AitM toolkits are being designed to evade detection.
Before we dive in, it’s useful to keep in mind that while there is a lot of complication here, most of this happens in seconds and is transparent to the intended victim accessing from a real browser.
Step 1: Cloudflare Workers for the initial gateway
A key feature of the NakedPages kit is that it has several stages and redirections and, in order for it to operate as intended, the target has to arrive at the beginning. The first step involves visiting a URL that is simply a Cloudflare Worker. Cloudflare Workers are a serverless execution environment, a bit like AWS lambdas.
The benefit to the attacker is that this gives them a highly reputable primary domain as it is one owned and operated by Cloudflare. Flagging recently registered or uncategorized/rare domains for further analysis won’t work for this. For example, the URL used in this instance was the following:
hxxps://226028cc.502f135e3e036e726fba22d4.workers.devFor other examples of Cloudflare Workers being abused for phishing, check out this blog post from Trustwave.
Step 2: Cloudflare Turnstile for bot detection
The only purpose of the Cloudflare Worker is to act as a bot gateway to prevent automated analysis getting further than this point. For this it uses Cloudflare Turnstile. Turnstile is a highly effective tool for detecting the difference between bots and human users as a replacement for CAPTCHAs used by websites across the world.
If it doesn’t work transparently then you’ll probably see something like this:
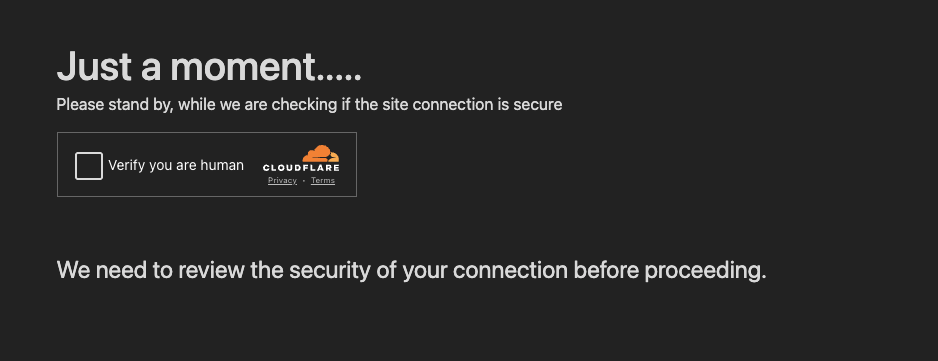
However, who else wants to keep out the bots? Well, phishers of course! There are many sandbox environments and other automated platforms out there, visiting every URL they come across in the search for malicious behavior. This stops many of them in their tracks as they never get past the Turnstile check.
Malicious use of Turnstile use has become much more common now. Examples include other criminal kits such as Tycoon, as well as open-source phishing tools focused on red teaming.
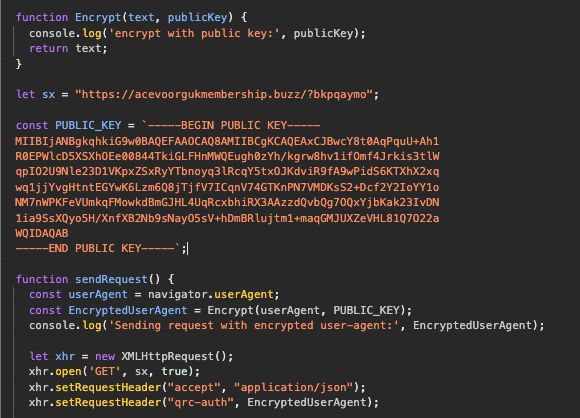
Step 3: Required URL parameters and custom auth headers
If you get past Turnstile, then you’ll finally be redirected to a more conventionally suspicious domain. However, you’ll need to supply the correct URL parameters and headers, or that request might behave differently.
Suspicious domains can be found and interrogated through other means, such as observing new domain registrations or certificate transparency logs. In this case, the phishers add other steps involving required URL parameters and custom headers. This means that a defender who knows the domain name can’t discover the malicious behavior just by making a simple HTTP(S) request to the domain.
The following code snippet shows how this operates. Bonus points for spotting how they actually forgot to implement their own RSA encryption function and instead send their “encrypted” user agents in clear text:
Step 4: Requiring JavaScript execution
Another aspect of the previous step is that it requires JavaScript to execute. That means defensive techniques that simply make HTTP(S) requests and scrape content will not automatically be able to follow the link without allowing JavaScript execution. This forces the use of dynamic sandbox techniques that actually load a DOM, as it’s almost impossible for static analysis to generically solve this problem.
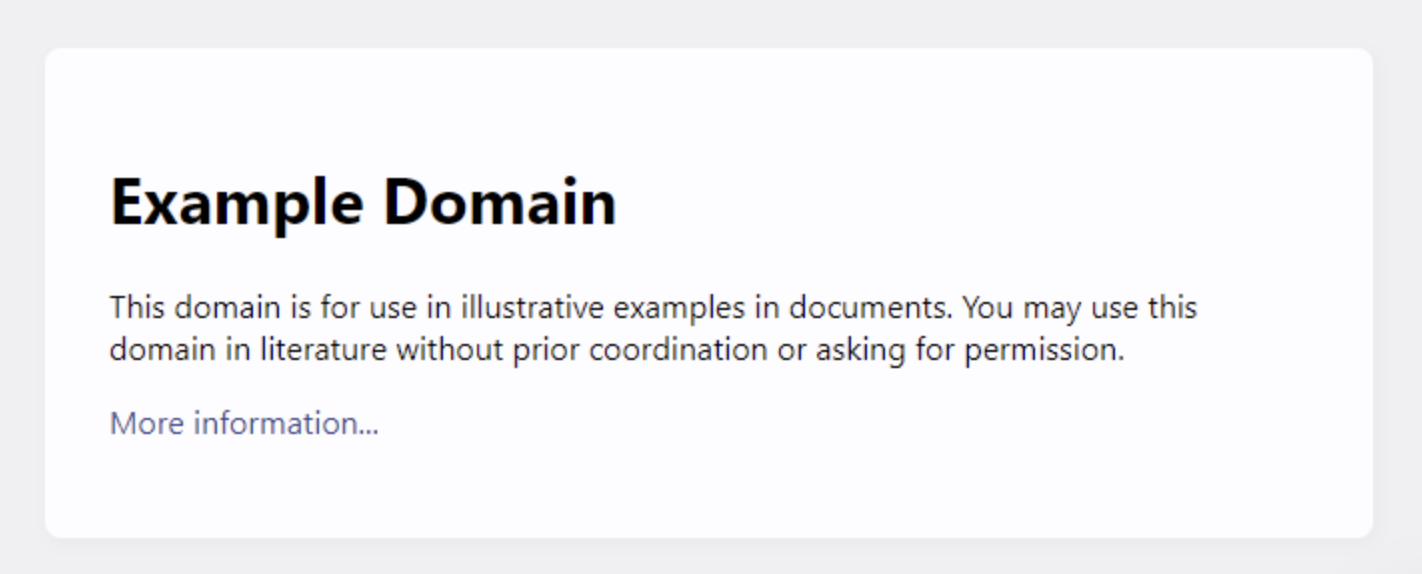
Step 5: Redirecting to legitimate domains
Attackers will also redirect to legitimate domains to mask their activity. Let’s say a defender has visited the attacker’s malicious domain without executing JavaScript or supplying the correct URL parameters. The attacker doesn’t want to activate their malicious phishing behavior at this point, so they need to do something benign instead. In this case, they simply redirect to https://example.com. Interestingly, EvilProxy has also been seen redirecting to example.com too:
Step 6: HTTP referer header masking
Maintainers of legitimate websites often look at the HTTP referer header to see where they are being linked from. This is often a critical task for businesses, particularly for things like marketing. However, what if employees spot strange redirects coming in from suspicious looking domains like the ones used by this phishing kit? Perhaps they might investigate those domains and/or tip off relevant security vendors and organizations.
Unless, of course, you were to use a service to mask the HTTP referrer – which is exactly what the phishing kit does in this case. NakedPages makes use of https://href.li/ as a service to strip the referral to ensure the redirection is performed anonymously. Rather conveniently, it seems the default example that https://href.li uses is… example.com:

Step 7: Loading balanced domains
You’re probably thinking: Step 7? Surely, if a victim’s browser has finally made it this far then the attackers would just serve up the malicious phishing content at this point, right? Well, we aren’t quite done yet. These initial gateway servers are one of the most important components to keep undetected, as existing phishing campaigns and (as yet unread) emails will be leading to them.
Once we get to the more obviously malicious phishing activity, there is a higher chance of detection and user reports. In this case the phishing kit actually retrieves a new URL to redirect to, along with a suitable JWT authentication parameter. The benefit of this is that when URLs/hostnames get flagged as malicious, blocked or otherwise taken down, the phishing kit can just redirect to other hostnames, and the attacker’s can keep updating with new URLs over time.
Below we can see an example of the response containing a URL, with a JWT auth parameter:
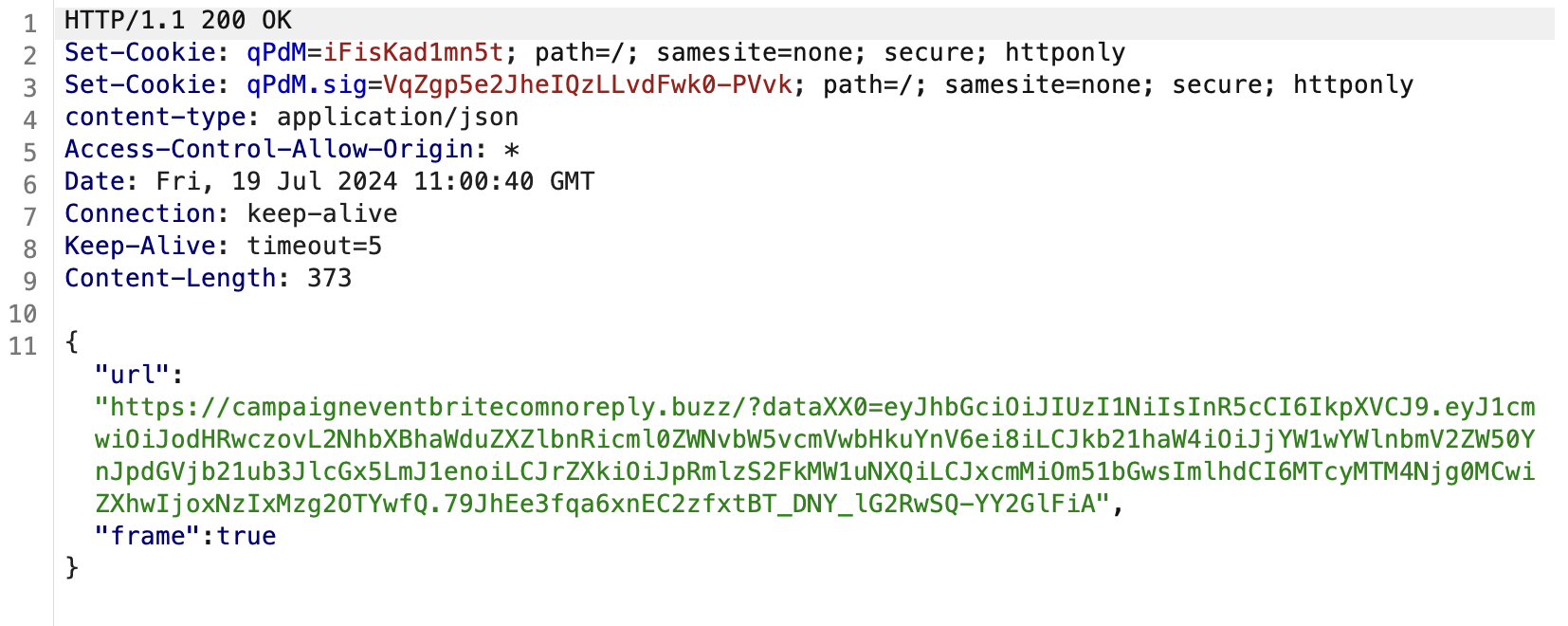
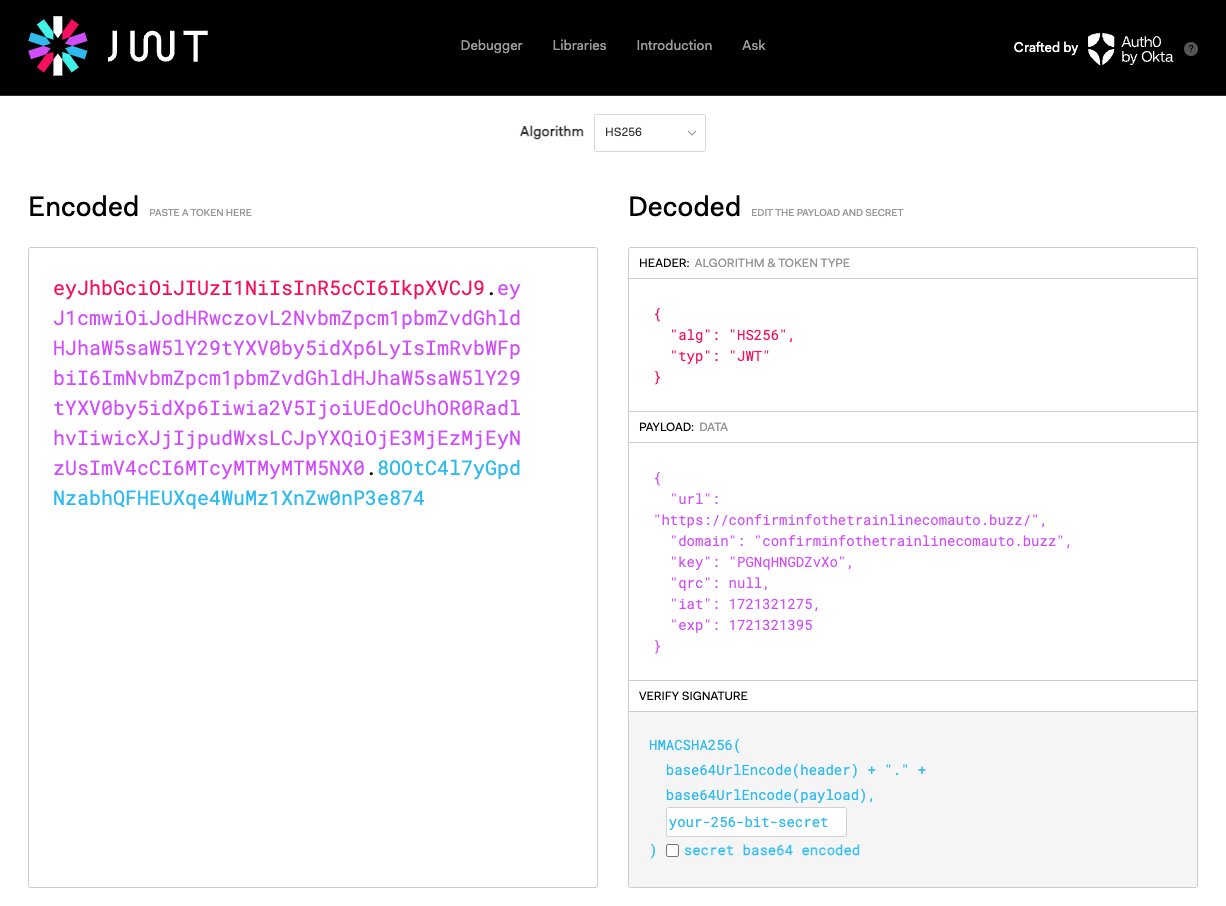
Automating this request in this example brings back around 20 different primary domains used for the final phishing attack. These domains are rotated over time as some are blocked and new ones are created.
Step 8: Breaking login page signatures
If all the previous checks have passed then a victim user is finally presented with a phishing page. The attacker has most closely emulated the sign-on page for live.com for Outlook in this case, though it also has some aspects from a business Microsoft login too, as we can see in the examples below:
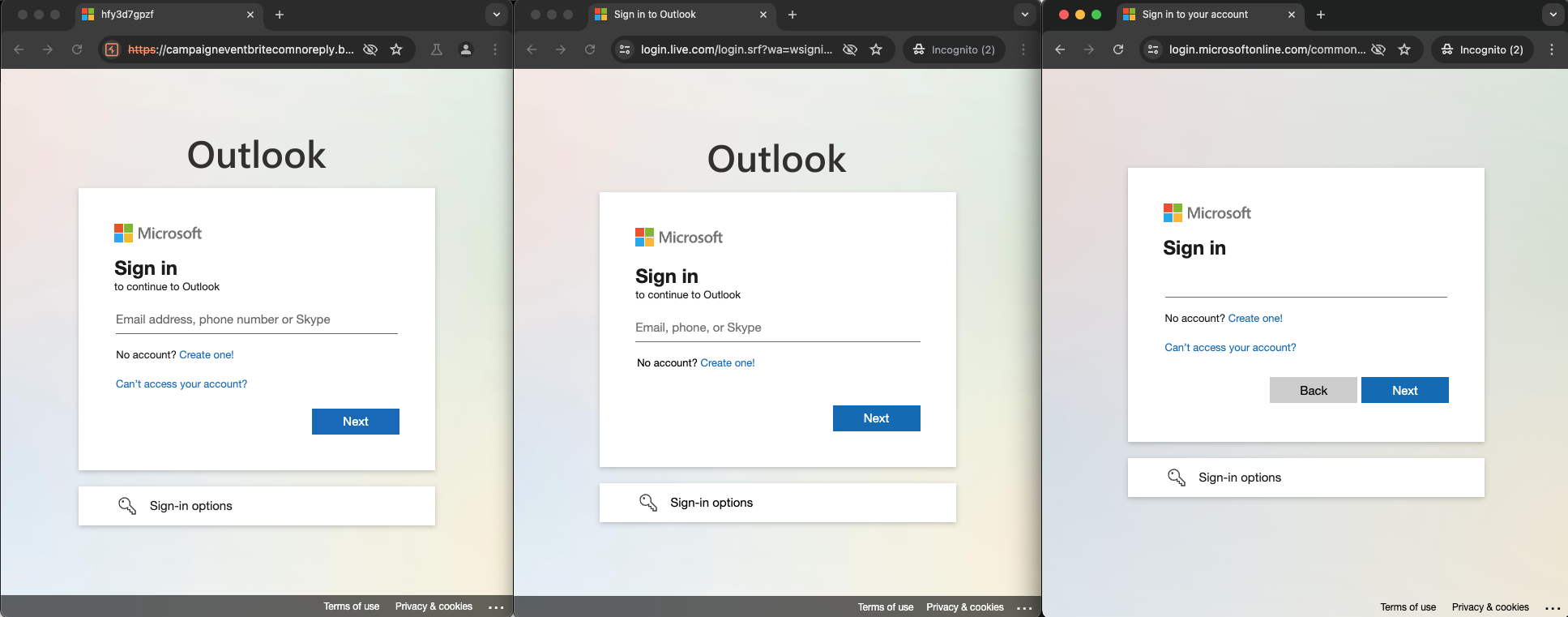
However, one obvious change can be seen in the HTML title in the tab header. This normally says something like “Sign in to Outlook” or “Sign in to your account”. In this case, the phishing kit has randomized the HTML title. One super easy way to detect websites pretending to be common login pages that have 1:1 cloned the website or are performing full reverse proxy AiTM techniques would be to search for obvious HTML content like this. Not many legitimate websites should have an HTML title of “Sign in to Outlook” other than Microsoft’s own legitimate domains for it, right?
Taking a closer look, we’ll see that the HTML, DOM and JavaScript etc. differ quite significantly from the true login pages, even if the visual appearance is very similar. One reason for this is to make it harder for defenders to simply signature on specific aspects of commonly spoofed login pages.
Step 9: B2B targeting
The final interesting aspect of this particular example is that it modifies its behavior during the login process depending on whether a personal Microsoft account or an organization account is used.
When entering an email address associated with a personal Microsoft account, or picking ‘personal account’ when prompted after entering an email address that is used for both purposes, the server will return a 302 redirect and send the user to https://login.live.com/ where they can then re-enter their credentials and login to Microsoft legitimately if they continue. This reduces the potential for detection further as no AitM phishing login will actually occur.
On the other hand, when using an organization account the phishing process continues as expected. This phishing campaign is exclusively targeting corp accounts and you could almost say it has a B2B (or is that A2B?) rather than B2C business model.
Conclusion
As you may have guessed from the extremely suspicious domains in use and examples of sloppy coding (like forgetting to implement an encryption function) the NakedPages kit is far from sophisticated. Despite this, the tricks that attackers are using to make detection and analysis more difficult seem to be quite effective when used in a layered model.
For example, at the time of writing this particular Worker had been up for at least two days and was currently only triggering 1 detection on VirusTotal.
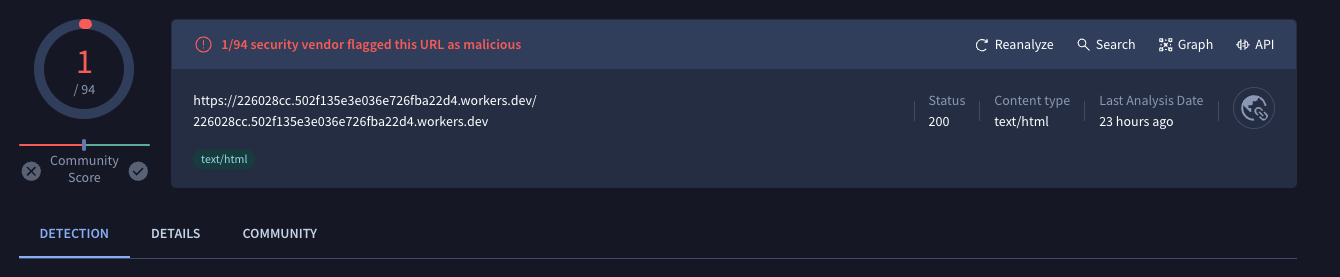
One key takeaway is that it’s near impossible to stay on top of all the phishing servers on the internet. Even the untargeted mass campaigns will initially be missed by TI feeds, let alone the targeted ones.
The best foot forward for resilience against these attacks is through the use of domain-bound MFA methods like WebAuthn. Common MFA methods like OTPs, SMS, push notifications etc. are routinely bypassed using AitM techniques that proxy the MFA authentication as well. Even if you are one of the few who use phishing-resistant MFA methods like WebAuthn or other passkeys, the devil is in the detail and we’ve seen MFA downgrade attacks being used to bypass them by choosing a phishable method that’s also active.
P.S. How did we detect this?
After all that, you might be wondering how we managed to automate a process to generically pass through all these detection evasion techniques – well the short answer is: We didn’t. Instead, we detected the act of an employee attempting to put their Microsoft password into a website that wasn’t Microsoft.
The TTP for phishing is effectively “trick someone into putting their valid credentials into the wrong site” – so detecting that behavior directly (the action of entering a legit password into the wrong site) can be a lot simpler and more effective than playing the cat-and-mouse detection → detection-evasion game.
Having said that, if you’re interested, here are the domain IOCs for this campaign:
226028cc[.]502f135e3e036e726fba22d4[.]workers[.]dev
acevoorgukmembership[.]buzz
alerteditorroyalsocietyorgnz[.]buzz
andymarshallsgeniuslocidigestghostiomghostio[.]buzz
blogresponseinsperitycom[.]buzz
campaigneventbritecomnoreply[.]buzz
charityexcellencer1technologytrustnewsorg[.]buzz
clerkenwelldesignweekcomnoreply[.]buzz
confirminfothetrainlinecomauto[.]buzz
healthestatejournalcomnoreply[.]buzz
mentalhealthdesignandbuildcomnoreply[.]buzz
noreplynotificationswhoopcom[.]buzz
stepexhibitionscomeventsupport[.]buzz
theathletice1theathleticcom[.]buzz
thekakahoonssubstackcom[.]buzz
